Logging
The Supabase Platform includes a Logs Explorer that allows log tracing and debugging. Log retention is based on your project's pricing plan.
note
These features are not currently available for self-hosting and local development.
This is on the roadmap and you can follow the progress in the Logflare repository.
Product Logs#
Supabase provides a logging interface specific to each product. You can use simple regular expressions for keywords and patterns to search log event messages. You can also export and download the log events matching your query as a spreadsheet.
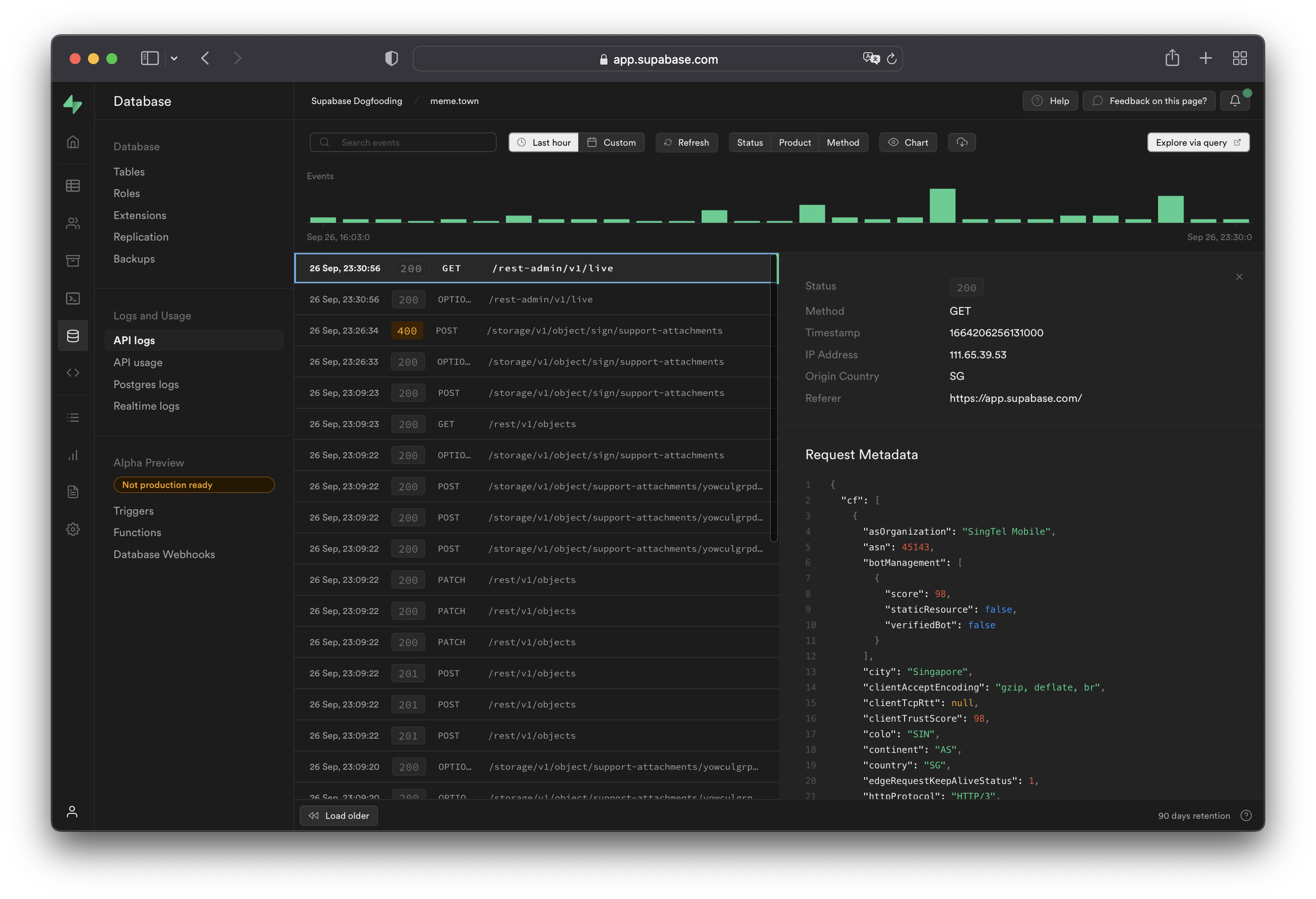
Logs Explorer#
The Logs Explorer exposes logs from each part of the Supabase stack as a separate table that can be queried and joined using SQL.
You can access the following logs from the Sources drop-down:
auth_logs: GoTrue server logs, containing authentication/authorization activity.edge_logs: Edge network logs, containing request and response metadata retrieved from Cloudflare.function_edge_logs: Edge network logs for only edge functions, containing network requests and response metadata for each execution.function_logs: Function internal logs, containing anyconsolelogging from within the edge function.postgres_logs: Postgres database logs, containing statements executed by connected applications.realtime_logs: Realtime server logs, containing client connection information.storage_logs: Storage server logs, containing object upload and retrieval information.
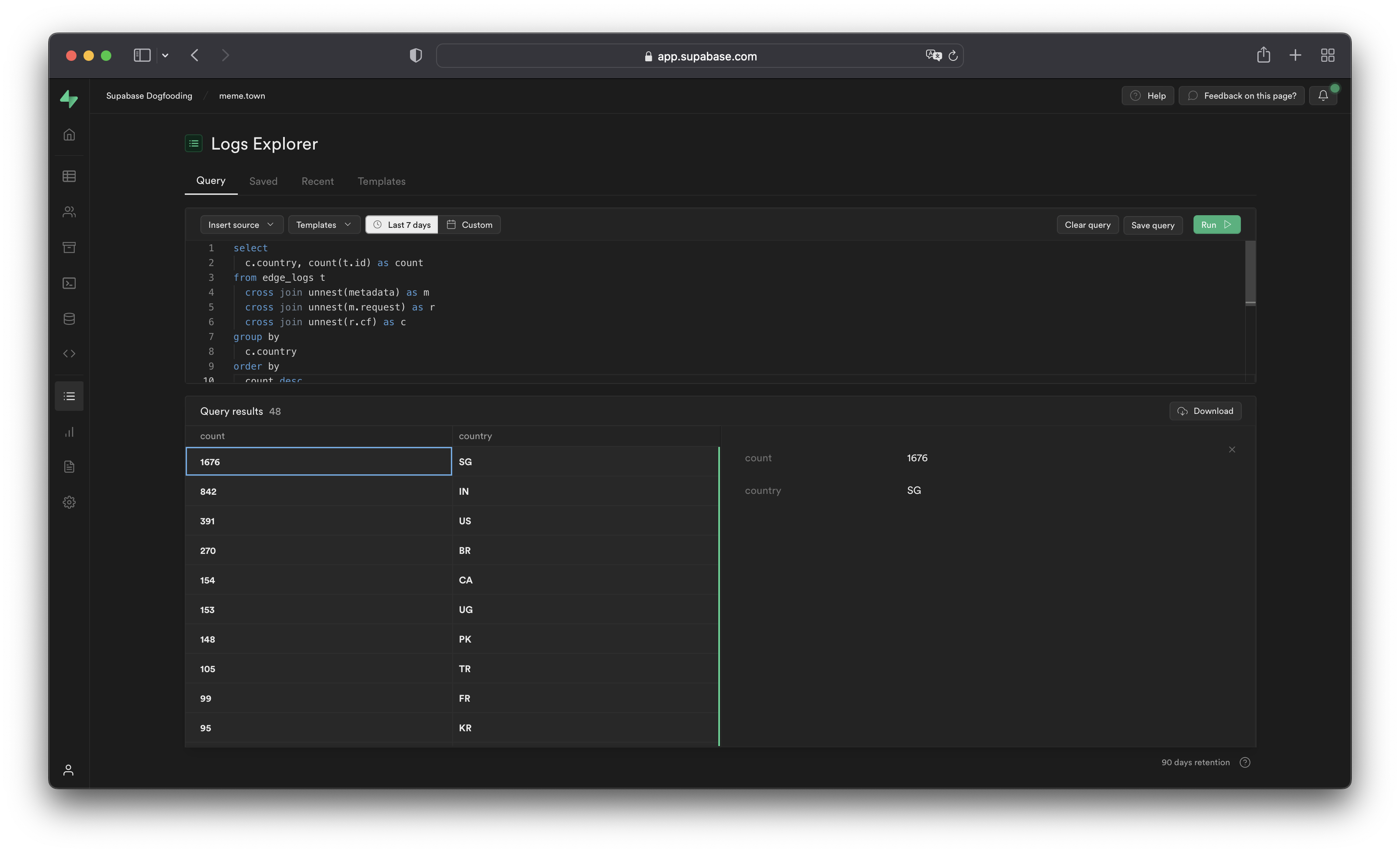
Querying with the Logs Explorer#
The Logs Explorer uses BigQuery and supports all available SQL functions and operators.
Timestamp Display and Behavior#
Each log entry is stored with a timestamp as a TIMESTAMP data type. Use the appropriate timestamp function to utilize the timestamp field in a query.
Raw top-level timestamp values are rendered as unix microsecond. To render the timestamps in a human-readable format, use the DATETIME() function to convert the unix timestamp display into an ISO-8601 timestamp.
1-- timestamp column without datetime() 2select timestamp from .... 3-- 1664270180000 4 5-- timestamp column with datetime() 6select datetime(timestamp) from .... 7-- 2022-09-27T09:17:10.439Z
Unnesting Arrays#
Each log event stores metadata an array of objects with multiple levels, and can be seen by selecting single log events in the Logs Explorer. To query arrays, use unnest() on each array field and add it to the query as a join. This allows you to reference the nested objects with an alias and select their individual fields.
For example, to query the edge logs without any joins:
1select timestamp, metadata from edge_logs t
The resulting metadata key is rendered as an array of objects in the Logs Explorer. In the following diagram, each box represents a nested array of objects:
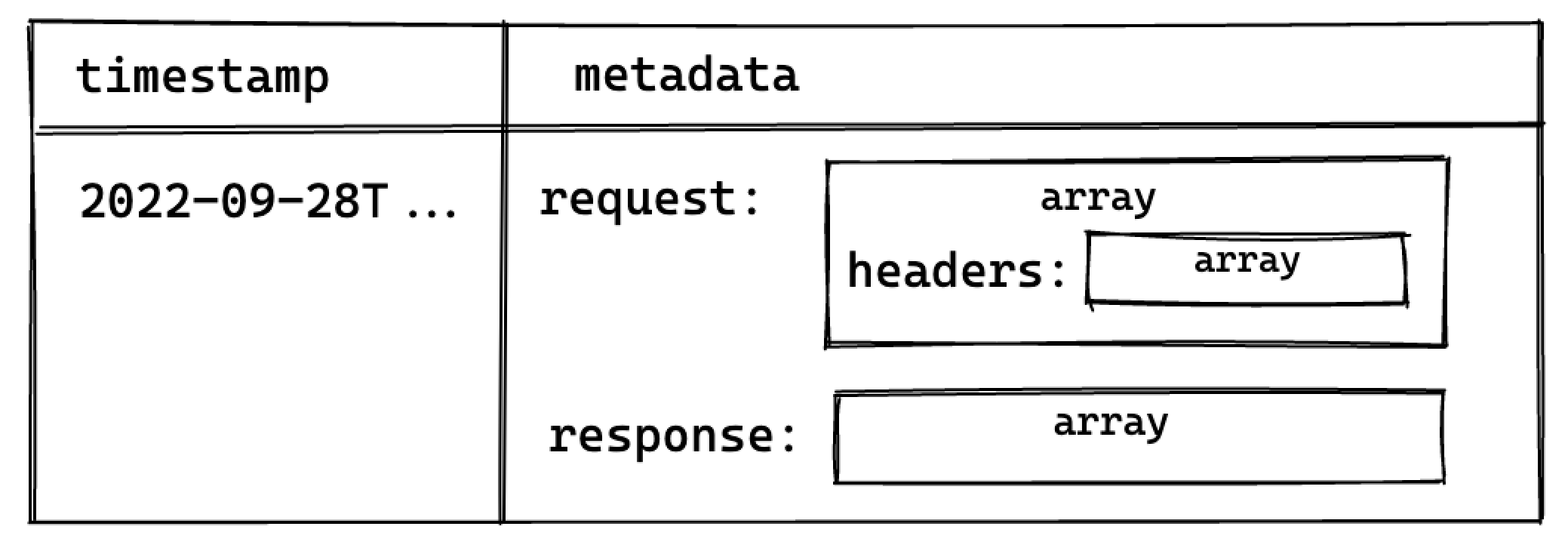
Perform a cross join unnest() to work with the keys nested in the metadata key.
To query for a nested value, add a join for each array level:
1select timestamp, request.method, header.cf_ipcountry 2from edge_logs t 3cross join unnest(t.metadata) as metadata 4cross join unnest(metadata.request) as request 5cross join unnest(request.headers) as header
This surfaces the following columns available for selection:
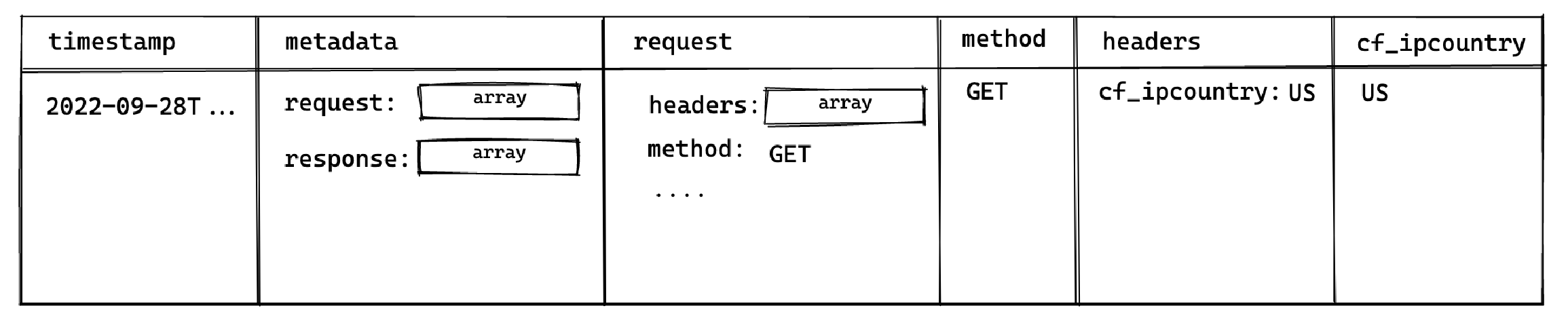
This allows you to select the method and cf_ipcountry columns. In JS dot notation, the full paths for each selected column are:
metadata[].request[].methodmetadata[].request[].headers[].cf_ipcountry
LIMIT and Result Row Limitations#
The Logs Explorer has a maximum of 1000 rows per run. Use LIMIT to optimize your queries by reducing the number of rows returned further.
Best Practices#
- Include a filter over timestamp
Querying your entire log history might seem appealing. For Enterprise customers that have a large retention range, you run the risk of timeouts due additional time required to scan the larger dataset.
- Avoid selecting large nested objects. Select individual values instead.
When querying large objects, the columnar storage engine selects each column associated with each nested key, resulting in a large number of columns being selected. This inadvertently impacts the query speed and may result in timeouts or memory errors, especially for projects with a lot of logs.
Instead, select only the values required.
1-- ❌ Avoid doing this 2select 3 datetime(timestamp), 4 m as metadata -- <- metadata contains many nested keys 5from edge_logs t 6cross join unnest(t.metadata) as m; 7 8-- ✅ Do this 9select 10datetime(timestamp), 11r.method -- <- select only the required values 12from edge_logs t 13cross join unnest(t.metadata) as m 14cross join unnest(m.request) as r
Examples and Templates#
The Logs Explorer includes Templates (available in the Templates tab or the dropdown in the Query tab) to help you get started.
For example, you can enter the following query in the SQL Editor to retrieve each user's IP address:
1select datetime(timestamp), h.x_real_ip
2from edge_logs
3 cross join unnest(metadata) as m
4 cross join unnest(m.request) AS r
5 cross join unnest(r.headers) AS h
6where h.x_real_ip is not null and r.method = "GET"